





排列3571246的逆序数探究
在数学与计算机科学中,排列和逆序数是两个基础而重要的概念,排列指的是从n个不同元素中取出m个元素(m≤n)进行排序的所有可能方式,而逆序数则用来衡量一个排列中逆序对的数量,即对于任意一对元素,如果前面的元素大于后面的元素,则称这对元素为一个逆序对,本文将深入探讨排列“3571246”的逆序数计算过程及其在数学与编程中的应用。
逆序数的定义与性质
逆序数在数学中有着广泛的应用,特别是在组合数学、统计学以及算法设计中,对于一个长度为n的排列P,其逆序数定义为所有不满足P[i] < P[i+1](对于所有i=1,2,...,n-1)的i的个数,简而言之,逆序数衡量了排列中“大数在前、小数在后”的元素对数量。

排列3571246的逆序数计算
为了计算排列“3571246”的逆序数,我们可以采用以下步骤:
- 逐一检查每个元素:从左到右遍历排列中的每个元素,检查其是否大于右侧的元素,如果大于,则计数器加一。
- 具体计算:对于排列“3571246”:
- 3:不小于右侧任何元素(无逆序对)
- 5:大于1(一个逆序对)
- 7:大于2、4、6(三个逆序对)
- 1:大于2、4、6(三个逆序对)但已计算过与5的逆序对,故总计两个新的逆序对
- 2:大于4、6(两个逆序对)但已计算过与7、1的逆序对,故总计一个新逆序对
- 4:大于6(一个逆序对)但已计算过与7、1、2的逆序对,故不再增加新的逆序对
- 6:无右侧元素(不增加逆序对) 综上,总共有3+2+1+0=6个逆序对,即该排列的逆序数为6。
编程实现与算法优化
虽然手动计算上述排列的逆序数相对简单直观,但在处理大规模数据时,手动计算将变得不切实际,利用编程语言实现高效的算法显得尤为重要,以下是一个简单的Python程序示例,用于计算任意给定排列的逆序数:
def calculate_inversion_count(arr):
n = len(arr)
inversions = 0
for i in range(n):
for j in range(i+1, n):
if arr[i] > arr[j]:
inversions += 1
return inversions
arr = [3, 5, 7, 1, 2, 4, 6]
print("The inversion count of the given permutation is:", calculate_inversion_count(arr))
此程序通过两层循环遍历所有元素对,并计算不满足顺序条件的对数,虽然这种方法在处理小规模数据时效率尚可,但对于大规模数据集而言,其时间复杂度为O(n^2),效率较低,为了优化性能,可以采用更高效的算法如归并排序中的“在线”计算方法或使用树状数组(Fenwick Tree)等高级数据结构来减少时间复杂度至O(n log n),对于本例中的简单应用场景,上述简单实现已足够。
数学与编程的交叉应用
在计算机科学中,逆序数的概念不仅用于理论探讨,还广泛应用于多个领域:
- 排序算法:许多排序算法如归并排序和快速排序在实现过程中会自然地计算出数组或列表的逆序数,这为评估算法性能提供了直接指标。
- 数据压缩:在数据压缩算法中,通过分析数据的逆序性可以优化存储和传输效率,在处理具有大量重复元素的序列时,通过重新排列以减少逆序数可以显著降低数据熵。
- 算法设计:在算法设计中,了解特定问题的逆序数可以帮助设计更高效的解决方案,在处理某些类型的图论问题时,了解边的相对顺序(即逆序数)可以简化问题模型或优化搜索策略。
- 统计与机器学习:在统计分析和机器学习领域中,数据的局部顺序性(如时间序列分析)可以通过其逆序数来分析,从而揭示数据中的潜在模式或异常点。
通过对排列“3571246”的逆序数计算过程及其在数学与编程中的应用探讨,我们可以看到这一基础概念在多个领域中的重要性,无论是理论上的数学推导还是实践中的编程实现,理解并掌握逆序数的概念都是解决相关问题的基础,随着数据量的增长和算法复杂度的提升,如何高效地计算和利用逆序数成为了一个重要的研究方向,随着算法和数据结构的不断进步,我们期待看到更多基于逆序数的创新应用和优化方法。
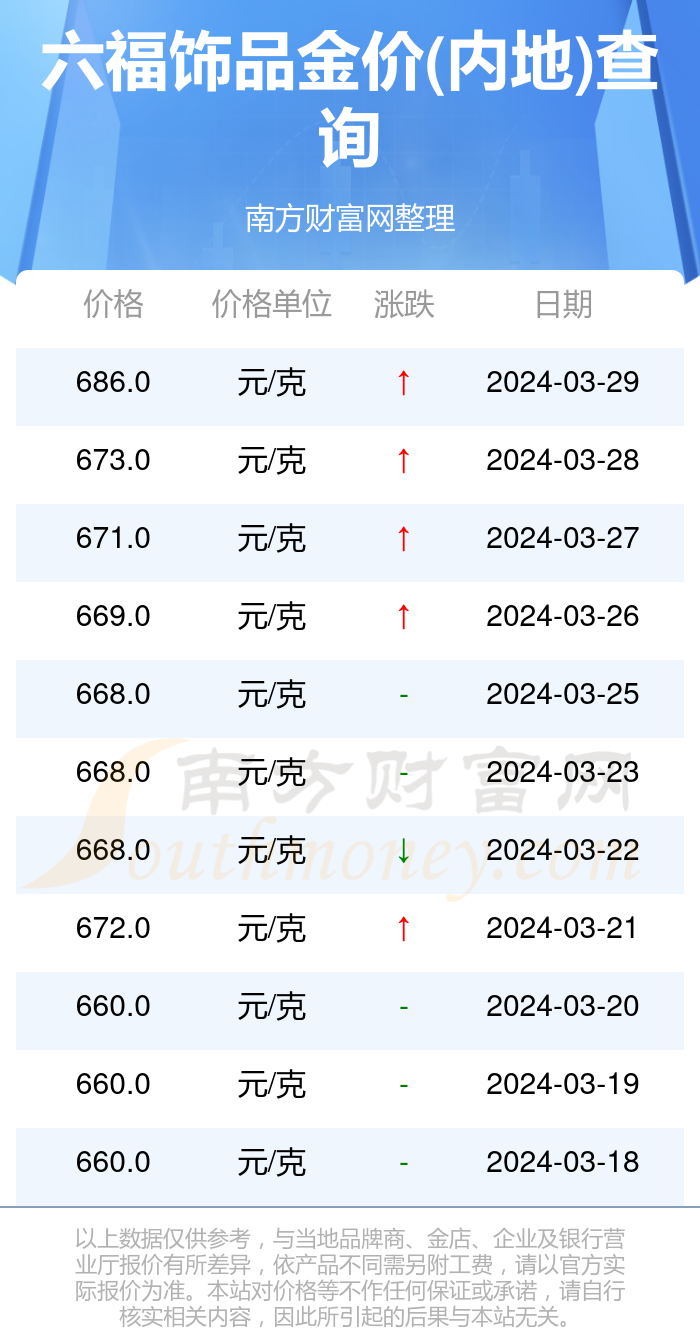

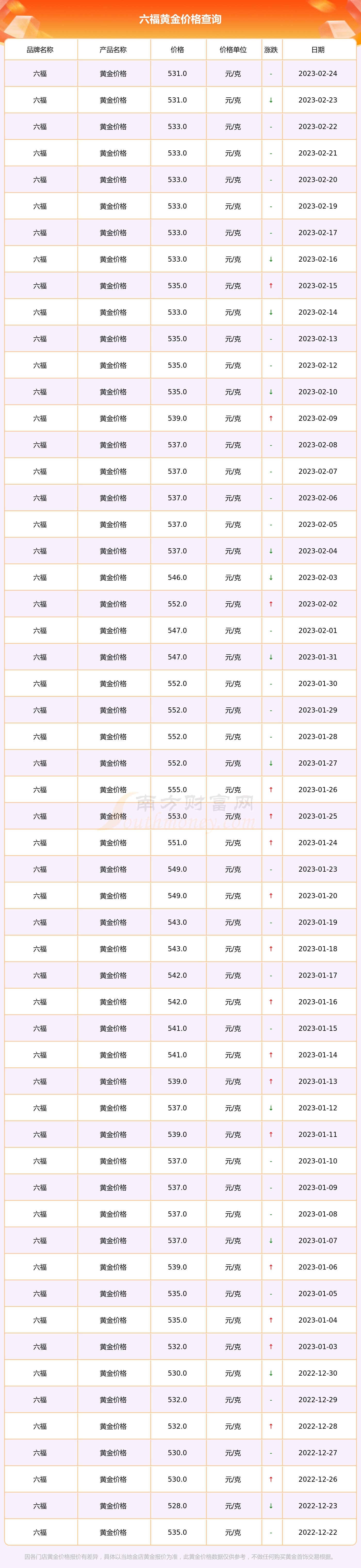



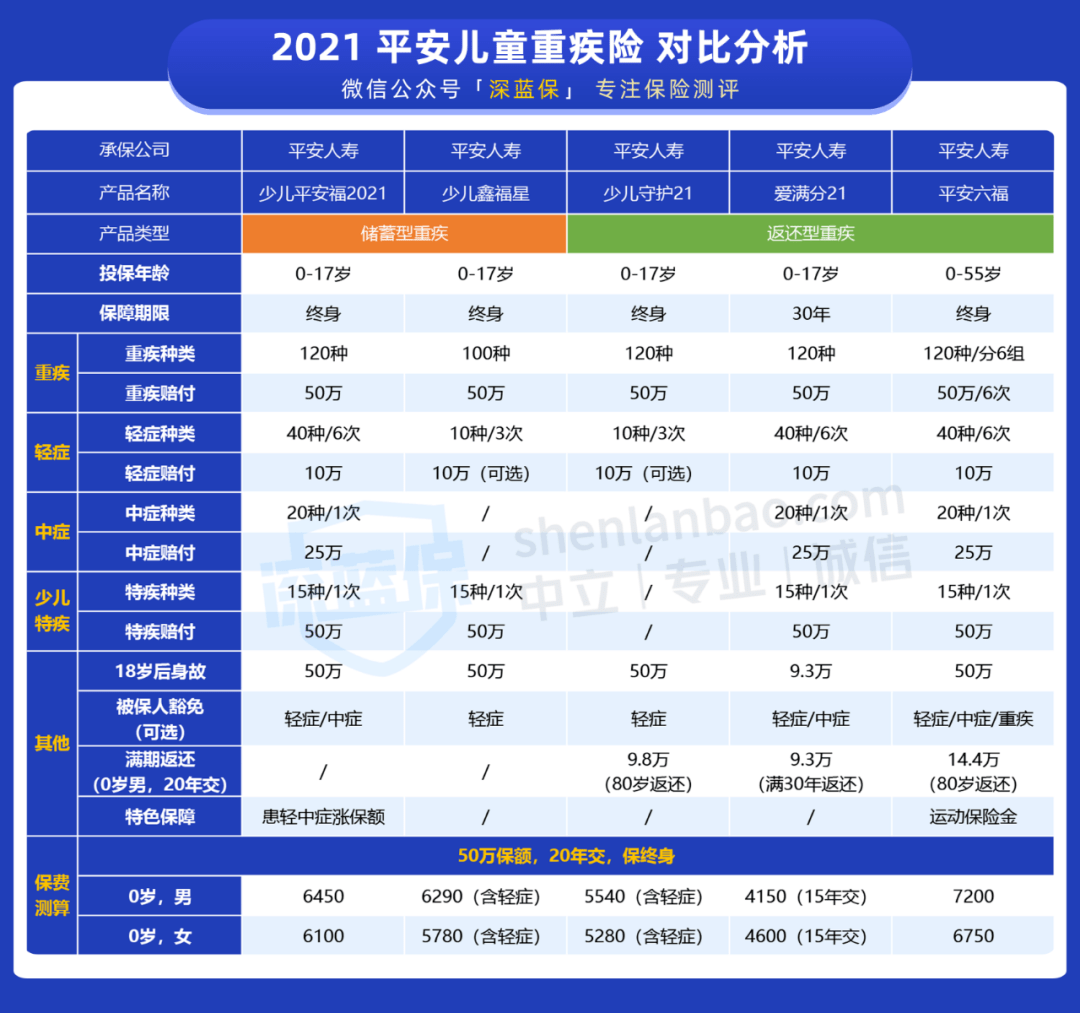
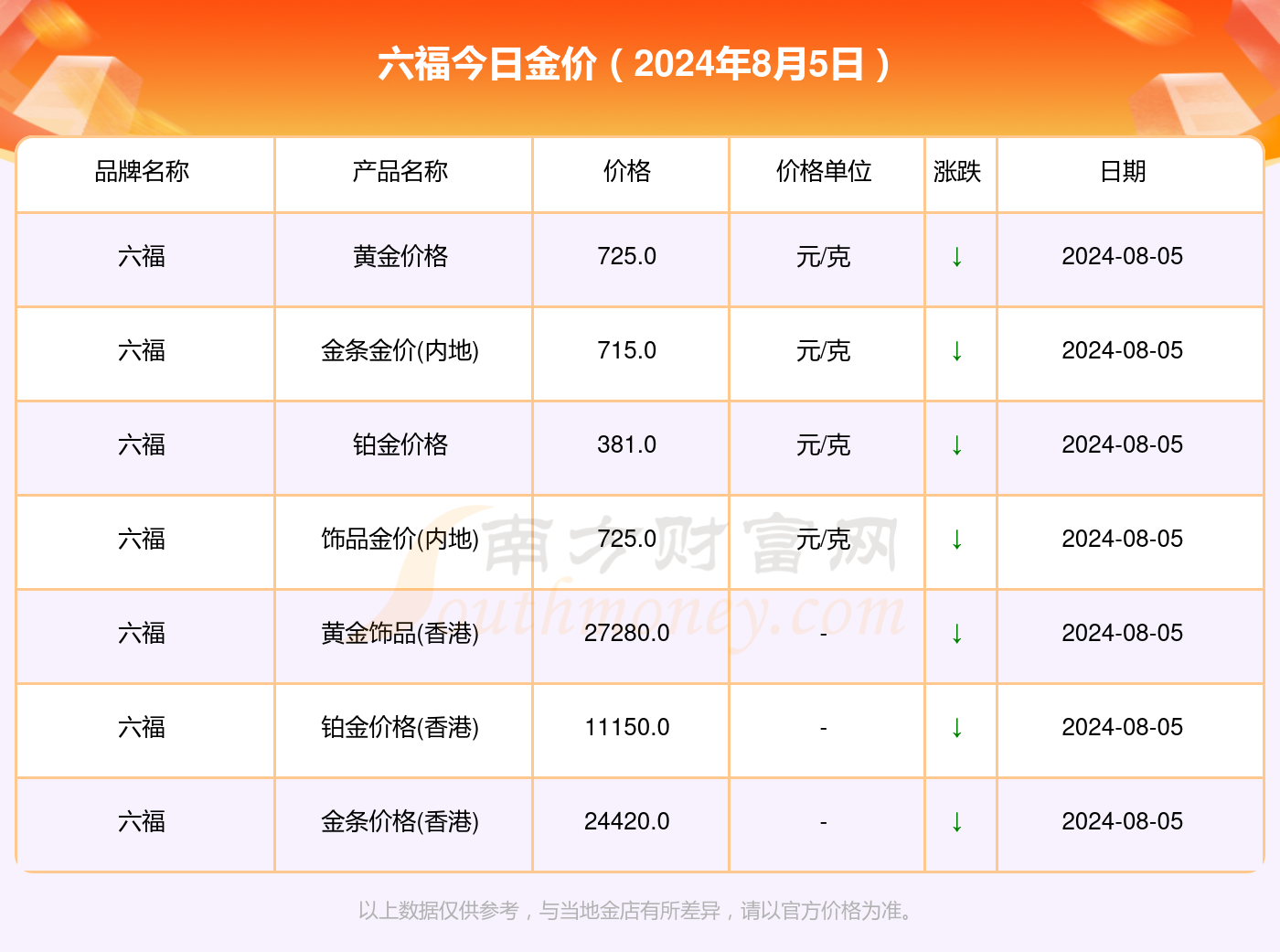
 京公网安备11000000000001号
京公网安备11000000000001号 鲁ICP备09025279号-1
鲁ICP备09025279号-1
还没有评论,来说两句吧...